1. Bug 在哪里?
看完 PIE 模型那一篇文章,我们已经了解了关于 Bug 的若干概念。通过学习 PIE 模型,我们了解了从程序员在程序中写下错误的代码,形成 fault,到错误的代码被执行导致错误的中间状态产生 error,最后软件运行出现能够被观测到的错误的结果造成 failure 的这样一个过程。
在这样一条因果链中执行感染传播这三个条件缺一不可。学习了这些知识是不是就意味着 Bug 的神秘面纱已经就此被我们揭开了?很遗憾并不是的,事实上我们有时甚至对于很多 Bug 的简单问题都无法做出准确的回答。
我们首先关注第一个问题,Bug 在哪里?我们可能无法说清楚程序当中到底哪里存在 fault。考虑下面这样一段程序,它比较 x 和 y 这两个整数的大小,找出其中较大的并返回:
<span class="hljs-function"><span class="hljs-keyword">int</span> <span class="hljs-title">Max</span> <span class="hljs-params">(<span class="hljs-keyword">int</span> x, <span class="hljs-keyword">int</span> y)</span>
</span>{
<span class="hljs-keyword">int</span> mx = x;
<span class="hljs-keyword">if</span> (x > y) <span class="hljs-comment">// 这是一个 fault !!</span>
mx = y
<span class="hljs-keyword">return</span> mx;
}
<span class="hljs-comment">/*
* Test Input: 3 ,5
* Expected output: 5
* Output: 3
* Fail !!!!
*/</span>
显然这段程序是存在错误的,因为这条测试用例 x 等于 3,y 等于 5,预期结果等于 5,但是它的实际运行结果是 3,也就是说实际运行结果与预期结果不一致。我们尝试修改这段程序,把第四行由 if (x > y) 修改为 if (x < y)。修改之后,再次执行这条测试用例。这次实际运行结果 5 与预期结果 5 是一致的。
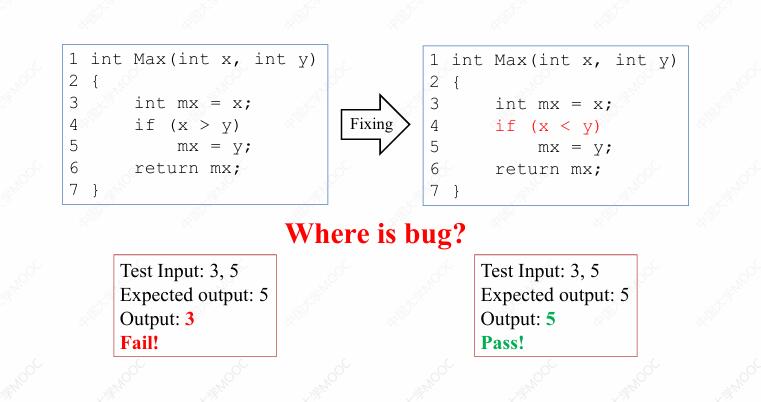
也就是说通过修改程序当中的第四行语句,程序当中的 Bug 被修复了。那么我们是否可以根据这样一个事实来声称程序当中的 fault,它就存在于程序的第四行?
可能有些人就不会同意这一观点。例如可能会有人这样修改程序,它会同时修改程序中的第三行和第五行,他把第三行由 mx = x 修改为 mx = y,而第五行则由 mx = y 修改为 mx = x ,也就是把 x 和 y 对于临时变量 mx 的赋值做了对调。
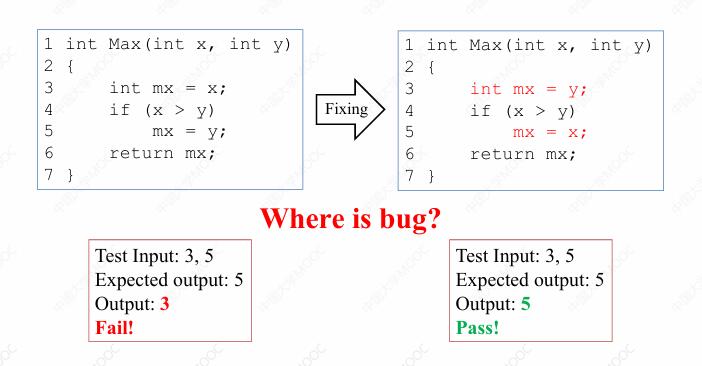
修改之后的程序,同样可以通过测试,也就是说程序当中的 Bug 被修复了。那么这个时候我们是否又可以根据这样一个事实来声称程序当中的 fault 同时存在于第三行和第五行?
所以这就导致一个问题,程序当中的 fault 到底存在于哪里?当然对于这样一个简单的案例,人们一般会认可最小修复的概念,也就是认为 fault 会存在于第四行语句,而不是同时存在于第三行和第五行语句。但是对于一些复杂的程序和复杂的修复,这样的判断也会变得比较困难。
2. Bug有几个?
除了难以确定 Bug 在哪里,我们有时也不知道程序当中的 Bug 到底有多少。我们在做 Debug 的时候,很多时候都都是试探性地进行 Debug,很少有人是在完全明确了缺陷在哪里之后才下手去修改程序的。还是交换大小的例子:
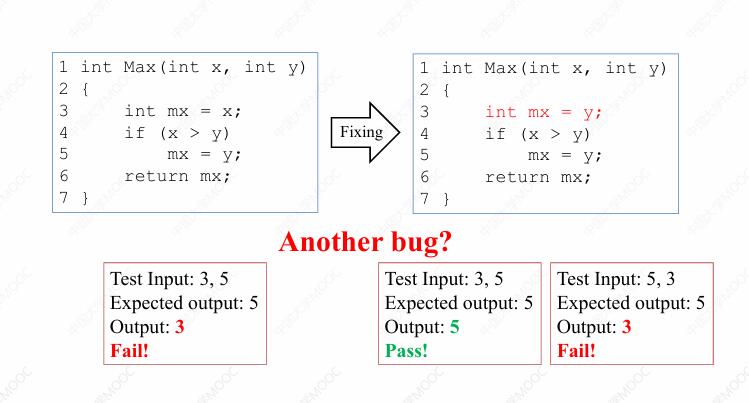
假设有人试探性地修改这个程序,他首先修改了程序当中的第三行,由 mx = x 修改为 mx = y 。非常凑巧的是,这个人在进行这样的修改之后,他发现 x = 3,y = 5,预期结果等于 5 的这条测试用例,实际运行结果也变成了 5,测试用例运行通过了!于是他欣喜若狂,我修复了一个 Bug!不过一个负责任的测试人员或者调试人员,工作肯定不会就此结束,测试还将继续进行。这次他换了一条测试用例,x = 5,y = 3,预期结果为 5,结果发现这条新的测试用例运行结果是 fail !
一个自然而然的想法是这个程序当中可能还存在着其他一些未被修复的 Bug。于是他进一步探索程序,这次他修改了第五行,把 mx = y 改成了 mx = x 。修改之后,第二条测试用例的运行结果也是 pass 了,事实上运行其他测试用例也都会得到 pass 的结果。
于是我们得出这样一个结论,程序此前存在两个 fault,那么这两个 fault 都被程序员修复了。但是也有人不这么认为,那么假设有另外一位程序员,他在在发现错误的运行结果之后,把第四行由 if (x > y) 修改为 if (x < y),测试用例全部运行通过了!于是他认为程序此前只存在一个 fault。
现在假设你是这两位程序员的经理,你如何评价这两位程序员的工作量?是不是第一位程序员修改了两个 bug,而第二位程序员只修复了一个 bug,这样的评价公平吗?显然是不公平地,程序中fault 的数量带有主观性与不确定性。
3. Fault之间可能相互耦合
除了 Bug 的位置和数量问题,更棘手的一个问题是:程序中不同的 fault 之间可能还会相互耦合,这种相互影响会带来一些违反直觉的现象。
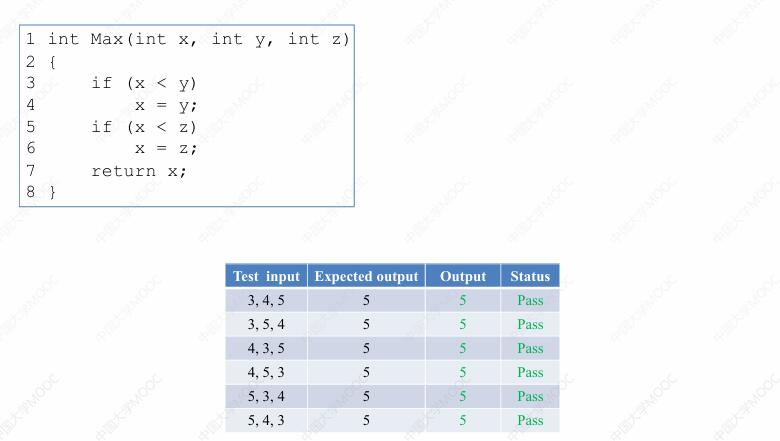
我们考虑这样一个程序,这个程序可以认为是前面我们所使用的程序的升级版本,这个程序会比较 xyz 三个整数,找出其中最大的一个并返回它的值。在这样一个正确的程序版本当中,我们运行 6 条测试用例,结果都是 pass:
现在我们可以人为的改动程序,将程序当中的其中一处给它改错,我们把第五行由 if x < z 改为 if x > z ,这个错误会导致所有 6 条测试用例的运行都是失败:
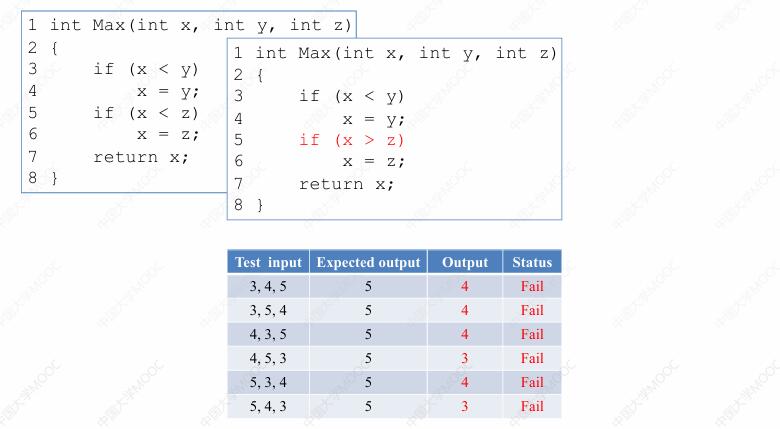
在这个基础上,我们继续向程序中添加 fault。这次我们把第七行由 return x 改为 return z,然后再次使用这 6 条测试用例来测试程序。这次我们会很惊讶地发现,这 6 条测试用例当中居然有 2 条测试用例通过了,只有 4 条测试用例运行结果是失败,也就是说这个时候测试用例的通过率是高于上一个版本的:

而在评价一个程序的质量时,我们可能会有一个非常朴素的想法,就是测试用例的通过率越高,说明程序的质量越高。但是在这个案例当中,我们发现包含两处 fault 的程序,它的测试用例通过率居然高于只包含一处 fault 的程序,所以你以后还敢再用测试用例的通过率来评价程序的质量吗?
好,以上这几点简单的问题,说明人们对于 Bug 的认识还存在相当的不足,对于 bug 的出现规律还需要进行更加深入的探索,不明白什么叫做 bug,当然会给寻找 bug 的工作带来困扰。