碎碎念
自从Web应用日益复杂,手工测试逐渐难以满足快速迭代的需求,自动化测试成为保障质量的关键。2004年,Selenium 项目诞生之初仅作为简单的 JavaScript 测试工具,经过二十年演进,其核心组件 WebDriver 在2018年被 W4C 正式确立为国际标准,成为 Web 自动化测试的标准工具。如今,Selenium WebDriver凭借跨语言、跨平台的统一API设计,已覆盖全球90%的Web自动化测试场景,尽管需要一定的编码基础,但其稳定性与扩展性仍无可替代。
2021年,随着Headless模式和容器化技术的普及,Selenium 迎来第四次重大更新,新增了更智能的元素等待策略与 DevTools 协议集成。本文将以 12306 网站测试为例,演示如何通过Python 绑定快速搭建可维护的自动化测试框架,从环境配置到断言优化,实现从零到持续集成的全流程实践。
关于这篇文章的完整实现代码,你可以在 Ethan的云盘中获取。
1. 环境安装
1.1 selenium 安装
你可以通过 pip 安装 selenium 包:
pip <span class="hljs-keyword">install</span> selenium
当然,比起直接用 pip 安装 ,我更推荐使用 Anaconda 来管理环境和依赖。你可以在左边栏 Environments 里方便的搜索到 selenium 包 :
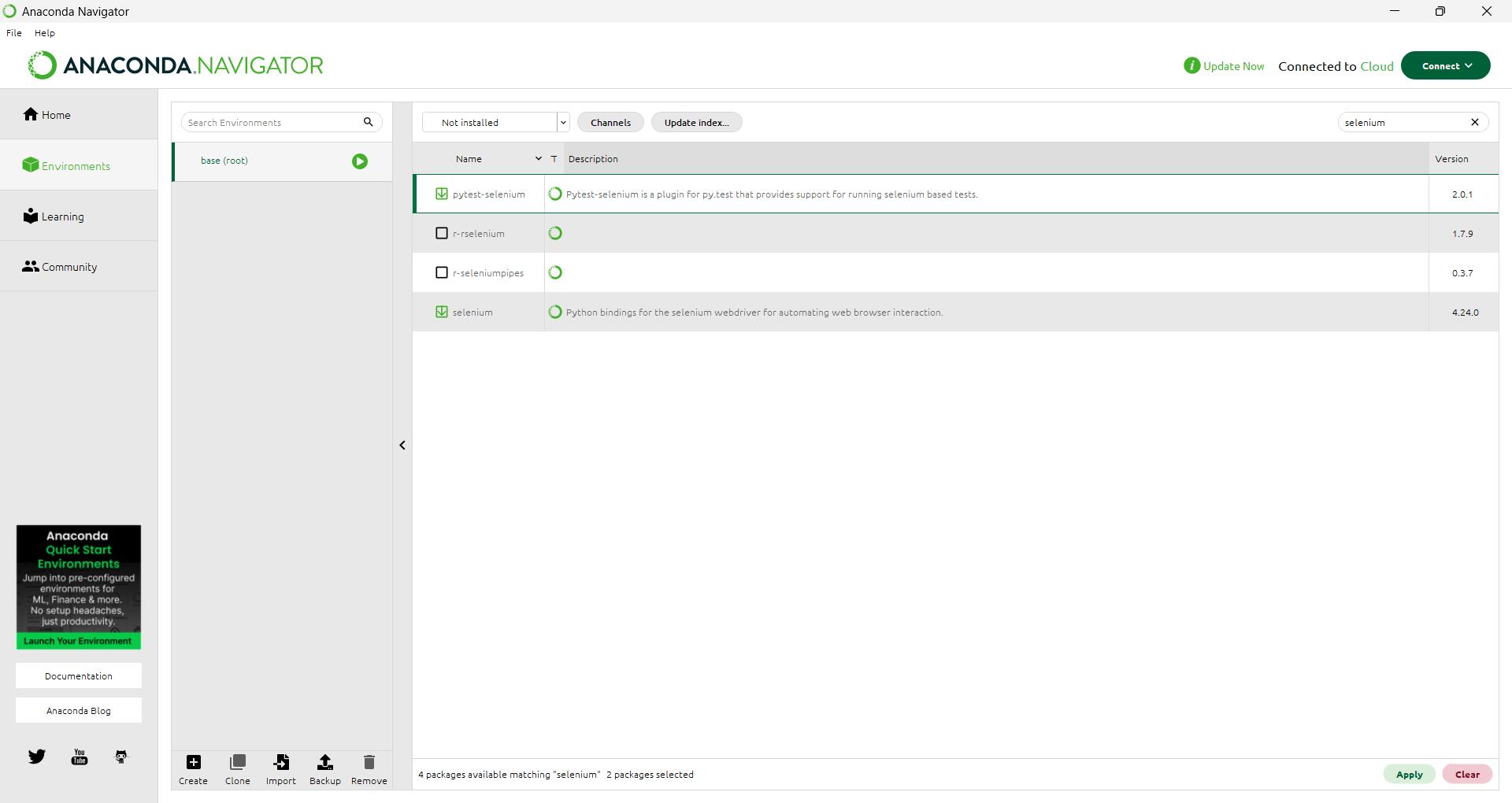
1.2 安装 WebDriver 驱动
以我使用的 Microsoft Edge 浏览器为例,在使用 Selenium WebDriver 进行自动化测试之前,我们需要先确定当前 Edge 的版本号,然后才能下载与之匹配的 WebDriver 驱动。
这是因为 Edge 浏览器和 WebDriver 之间存在严格的版本对应关系,如果版本不匹配,可能会导致自动化脚本无法正常运行。接下来,我将介绍如何快速查看 Edge 版本,并获取正确的 WebDriver。
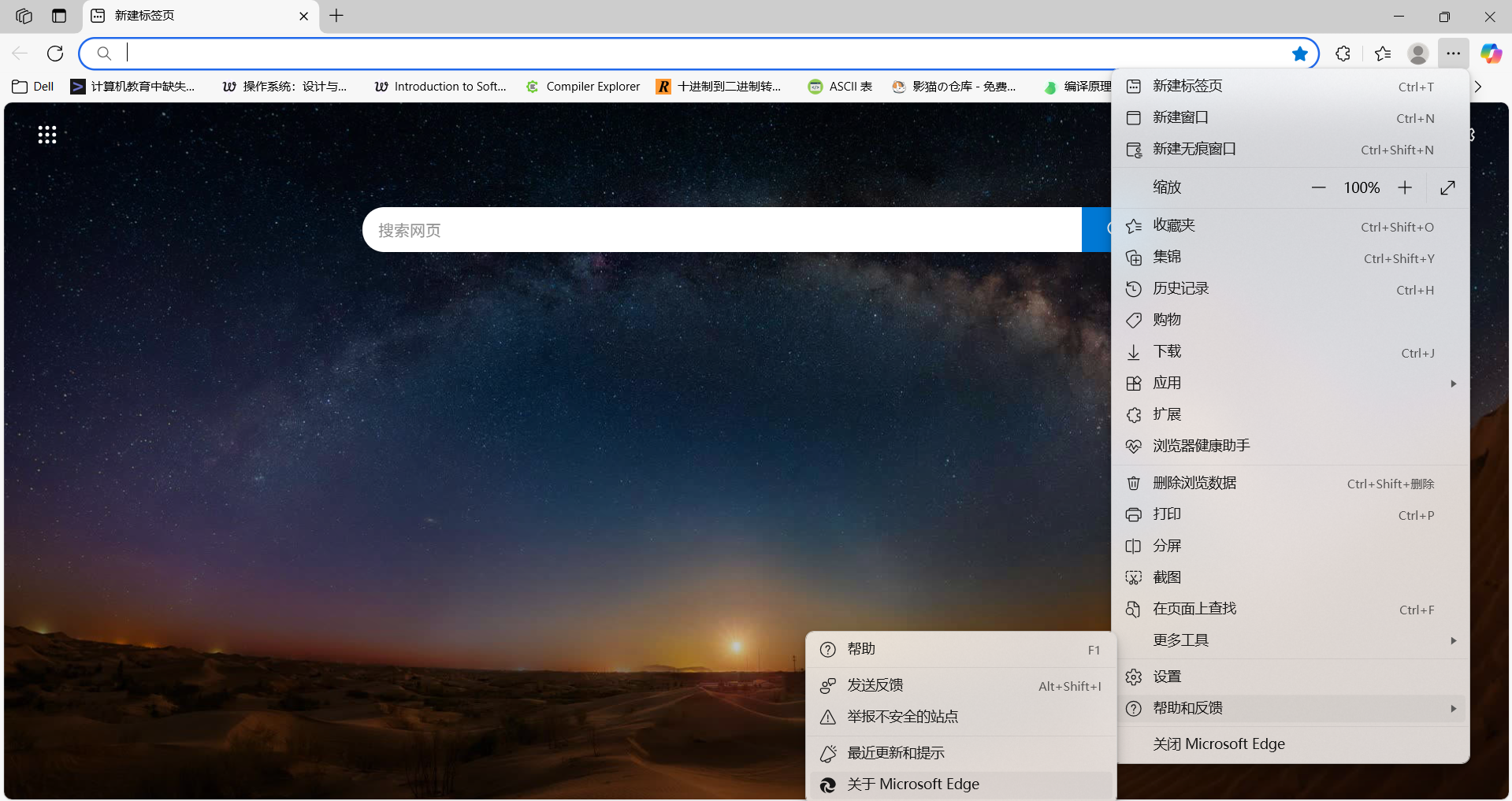
首先点击 Edge 浏览器右上角 ... 在工具栏中选择 帮助与反馈 → 关于 Microsoft Edge :
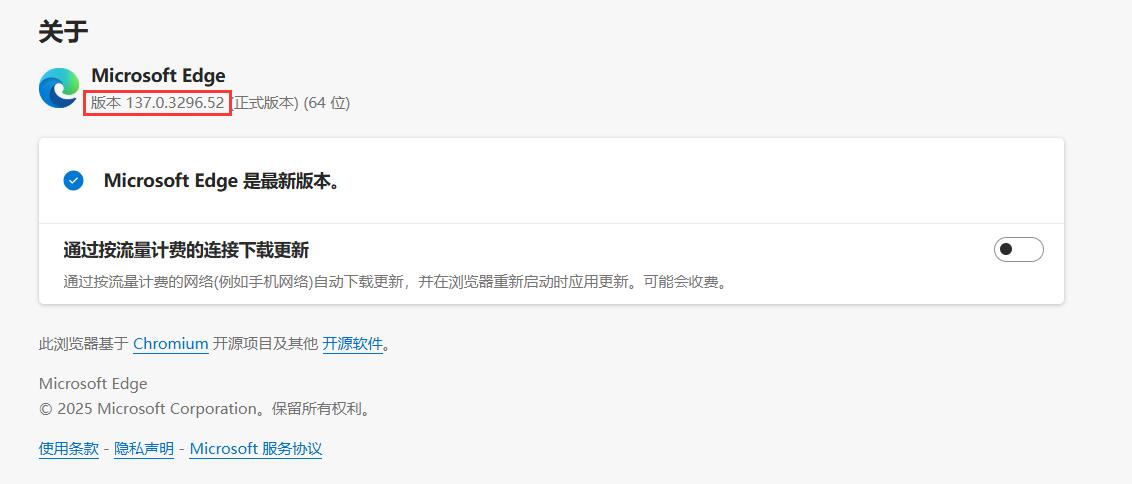
可以查看到我的 Egde 版本为 137.0.3296.52:
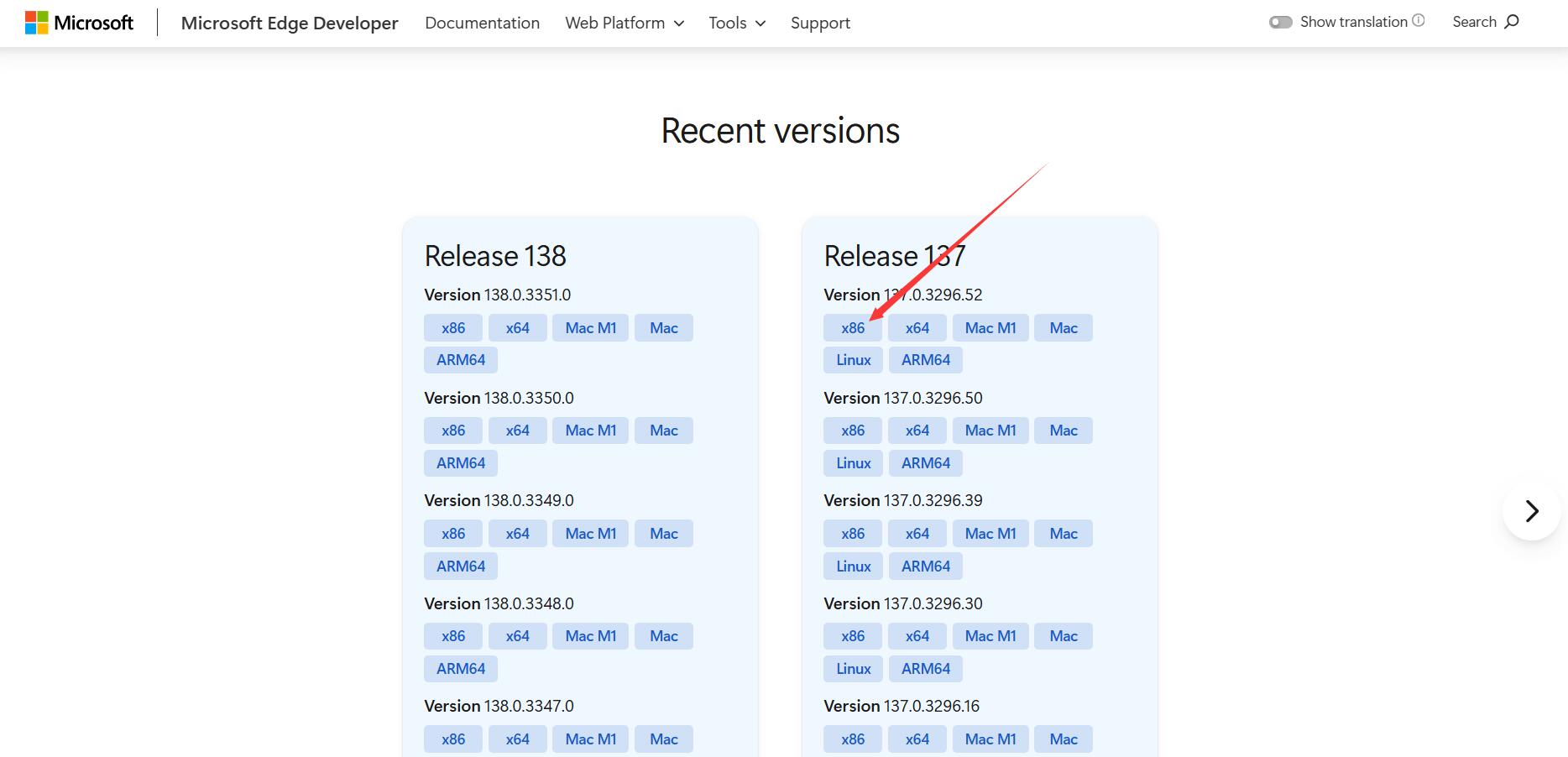
然后通过 Microsoft Edge 开发人员工具来获取对应版本的 WebDriver 驱动:
解压下载的压缩包,将里面的 msedgewebdriver.exe 重命名为 MicrosoftWebDriver.exe 并设置环境变量:
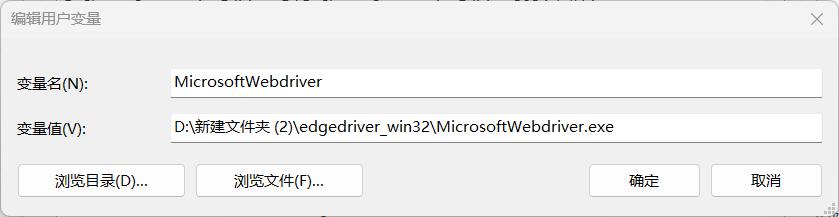
1.3 测试是否安装成功
创建文件 InstallTest.py 复制下面代码并运行,如果能弹出 Edge 窗口并获取百度首页则安装成功。
<span class="hljs-meta"># InstallTest.py</span>
<span class="hljs-meta"># author : ethan</span>
from selenium import webdriver
browser = webdriver.Edge()
browser.<span class="hljs-keyword">get</span>(<span class="hljs-string">"http://www.baidu.com"</span>)
2. 任务背景
假设你是 12306 网站的测试工程师,需要对南京至上海某日的:
- 符合要求的车次数量;
- 历时最短的车次;
- 这个/这些车次的出发时间和到达时间。
进行测试。首先把任务进行拆分:
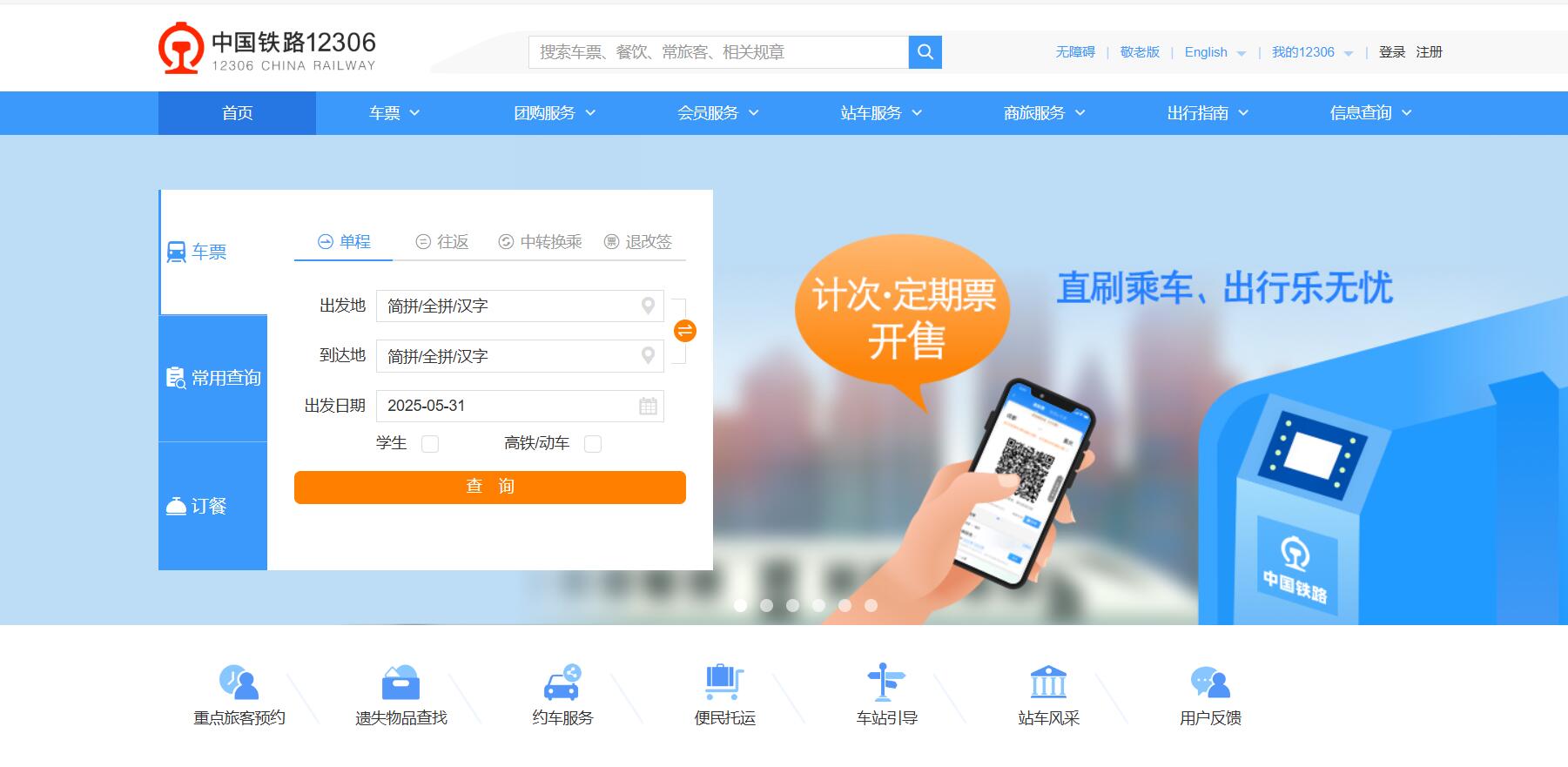
第一步:在 12306 网站首页上使用单程车票查询的功能查询南京至上海任意日期的车票,点击查询按钮后进入查询结果页面。
实践后可以发现:
- 出发地和到达地:可以通过键盘输入+鼠标点击或仅使用鼠标点击或仅使用键盘输入的方式选择;
- 出发日期:可以通过删除已有日期、键盘输入“xxxx-xx-xx”的日期格式并回车的方式选择或使用鼠标点击;
- 查询按钮:仅可以通过鼠标点击方式选择。
在第一步中,我们发现,需要学习 Selenium 如何打开浏览器,如何获取网页,如何模拟鼠标对指定元素进行点击,如何模拟键盘对指定元素进行输入。
第二步:在查询结果页面对车次类型、出发车站、到达车站、发车时间进行筛选,选择智能动车组、南京南站、上海虹桥站、发车时间范围12点至18点。
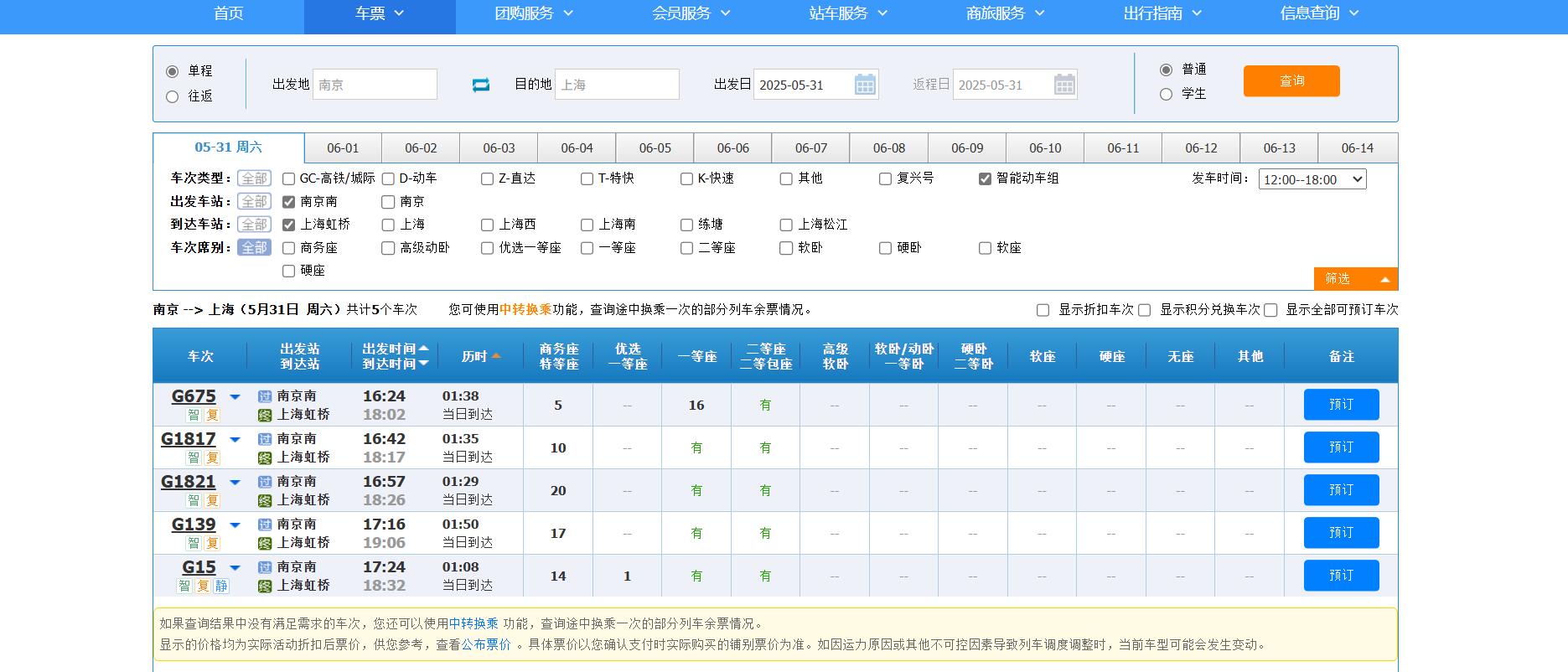
实践后可以发现:
- 车次类型:仅可以通过鼠标点击(自动化测试中可以选中元素+键入空格操作,学习完第三节你实操时会在 html 代码中发现这一点)选择智能动车组;
- 出发车站:仅可以通过鼠标点击选择南京南站;
- 到达车站:仅可以通过鼠标点击选择上海虹桥站;
- 发车时间:仅可以通过鼠标点击选择 12 点至 18 点。
在第二步中我们发现需要学习 Selenium 如何模拟鼠标对指定元素进行点击。
第三步:从下方查询结果中提取如下信息并通过控制台显示:
- 筛选后符合要求的车次数量;
- 历时最短的车次(如多个车次则都显示);
- 这个/这些车次的出发时间和到达时间。
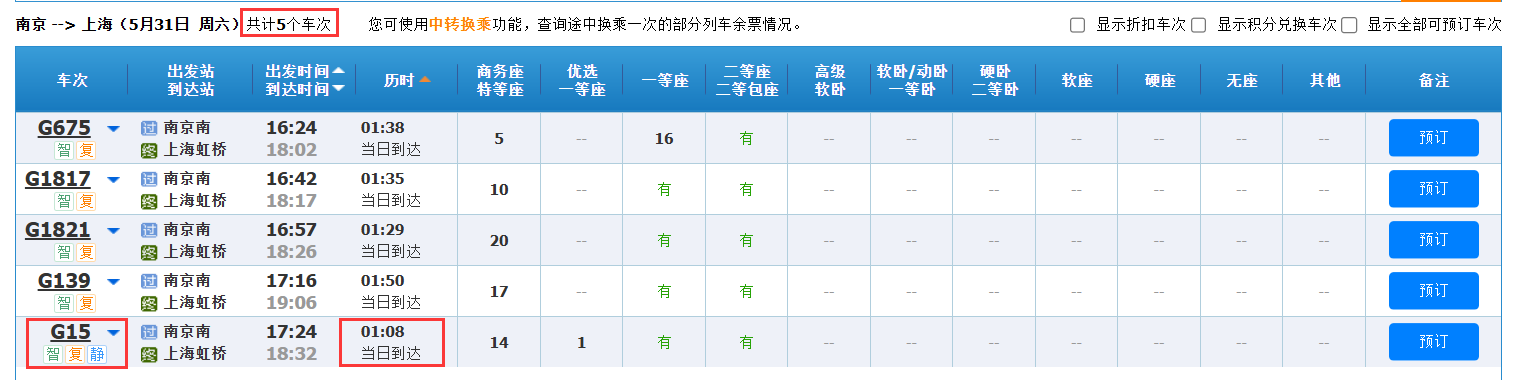
第三步中我们发现需要学习如何使用获取查询结果,并使用测试台输出
第四步:根据实际查询结果添加测试断言,验证筛选出的车次。
第四步中我们发现需要学习如何使用测试断言对获取的查询结果进行验证。关于如何 Selenium 如何与 Pytest 集成,我们将在下一篇文章中进行分析。
3. Selenium 基本用法
在第二节中,我们发现,完成任务的第一步和第二步需要学习 Selenium 如何打开浏览器,如何获取网页,如何模拟鼠标对指定元素进行点击,如何模拟键盘对指定元素进行输入。
3.1 初始化浏览器对象
在第一节中,我们已经将 Edge 驱动添加到环境变量中了,所以我们可以直接初始化界面。(如果没有添加,我们也可以指定绝对路径来使用):
<span class="hljs-meta"># Task.py</span>
<span class="hljs-meta"># author : ethan</span>
from selenium import webdriver
<span class="hljs-meta"># 初始化浏览器为chrome浏览器</span>
browser = webdriver.Edge()
<span class="hljs-meta"># 指定绝对路径的方式(可选)</span>
path = <span class="hljs-string">'...\chromedriver.exe'</span>
browser = webdriver.Edge(path)
<span class="hljs-meta"># 关闭浏览器</span>
browser.Edge()
3.2 访问页面
使用 browser 类的 get() 方法来访问页面,设置传入参数为待访问页面的URL地址即可。
<span class="hljs-meta"># Task.py</span>
<span class="hljs-meta"># author : ethan</span>
from selenium import webdriver
<span class="hljs-meta"># 初始化浏览器对象并打开12306网站</span>
browser = webdriver.Edge()
browser.<span class="hljs-keyword">get</span>(<span class="hljs-string">"https://www.12306.cn/index/"</span>)
browser.close()
3.3 定位页面元素
我们进入 12306 网站首页,打开开发人员工具。依次点击 从页面中选择一个元素进行检查(开发人员工具中,最上面箭头所指) → 网页中出发地的输入框 ,此时你可以在右侧找到选择到的 input 元素的 html 代码:
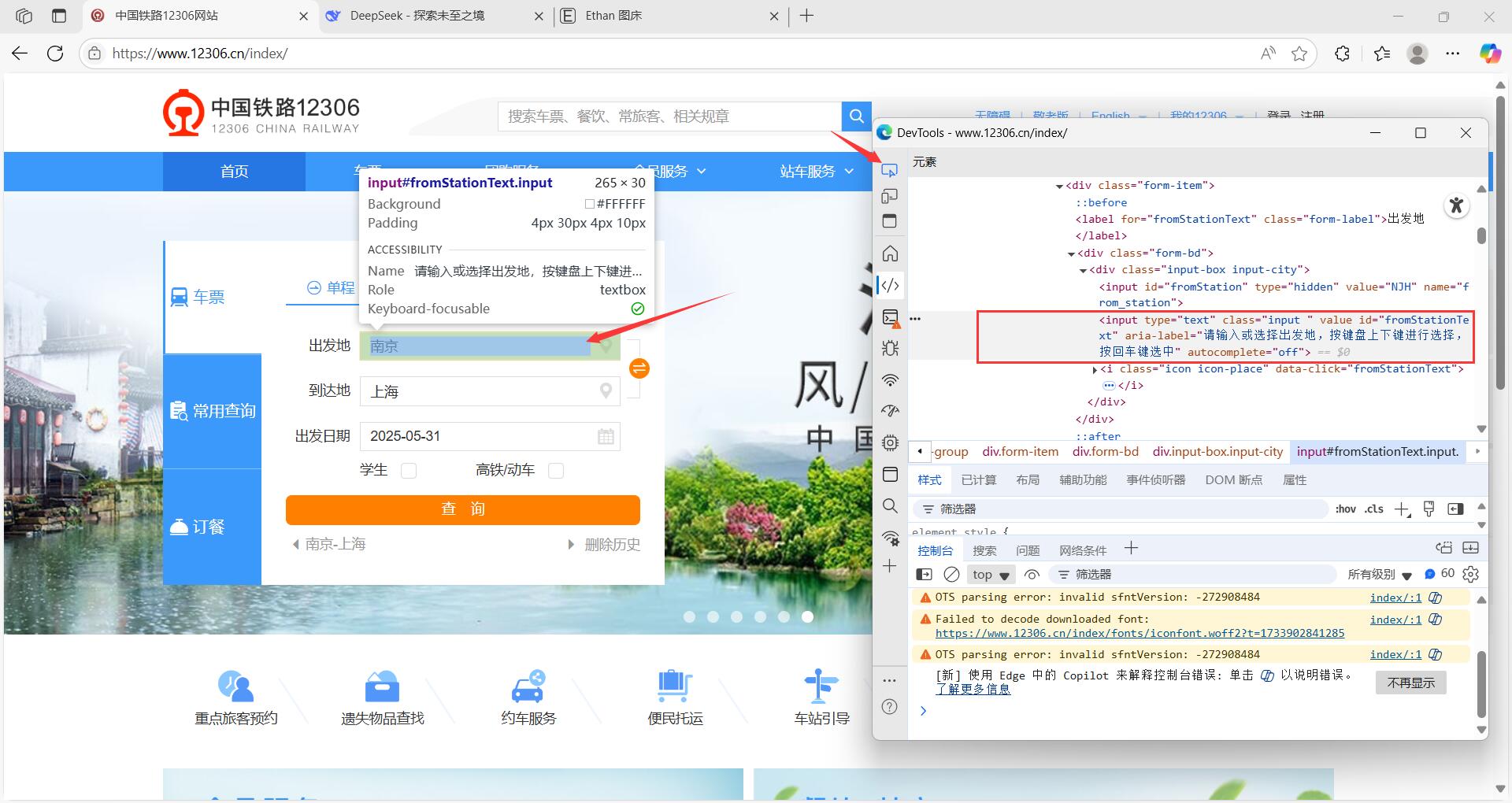
<input <span class="hljs-class"><span class="hljs-keyword">type</span></span>=<span class="hljs-string">"text"</span> <span class="hljs-class"><span class="hljs-keyword">class</span></span>=<span class="hljs-string">"input "</span> value=<span class="hljs-string">""</span> id=<span class="hljs-string">"fromStationText"</span> aria-label=<span class="hljs-string">"请输入或选择出发地,按键盘上下键进行选择,按回车键选中"</span> autocomplete=<span class="hljs-string">"off"</span>>
Selenium 提供了 find_element(by=“属性名”, value=“属性值”) 方法来方便我们定位页面元素。属性函数主要包括以下七种:
| 属性 | 函数 |
|---|---|
| CLASS | find_element(by=By.CLASS_NAME, value=‘’) |
| XPATH | find_element(by=By.XPATH, value=‘’) |
| LINK_TEXT | find_element(by=By.LINK_TEXT, value=‘’) |
| PARTIAL_LINK_TEXT | find_element(by=By.PARTIAL_LINK_TEXT, value=‘’) |
| TAG | find_element(by=By.TAG_NAME, value=‘’) |
| CSS | find_element(by=By.CSS_SELECTOR, value=‘’) |
| ID | find_element(by=By.ID, value=‘’) |
所以我们可以通过以下语句定位到出发地的输入框:
<span class="hljs-comment"># Task.py </span>
<span class="hljs-comment"># author : ethan </span>
<span class="hljs-built_in">from</span> selenium import webdriver
<span class="hljs-built_in">from</span> selenium.webdriver.common.<span class="hljs-keyword">by</span> import By
<span class="hljs-comment"># 初始化浏览器对象并打开12306网站</span>
browser = webdriver.Edge()
browser.<span class="hljs-built_in">get</span>(<span class="hljs-string">"https://www.12306.cn/index/"</span>)
<span class="hljs-comment"># 定位出发站输入框元素</span>
fromStationText = browser.find_element(<span class="hljs-keyword">by</span>=By.ID,<span class="hljs-built_in">value</span>=<span class="hljs-string">'fromStationText'</span>)
browser.<span class="hljs-built_in">close</span>()
3.4 模拟键盘操作
模拟键盘操作我们需要引入 Keys 类:
from selenium<span class="hljs-selector-class">.webdriver</span>
<span class="hljs-selector-class">.common</span>
<span class="hljs-selector-class">.keys</span> import Keys
在第二节的实践中,我们发现出发地和到达地可以通过键盘输入地点+回车键等选择;定位元素类提供了 send_keys 方法以供我们使用键盘对其进行操作:
<span class="hljs-comment"># 定位出发站输入框元素</span>
<span class="hljs-keyword">from</span>StationText = browser.find_element(by=By.ID,value='<span class="hljs-keyword">from</span>StationText')
<span class="hljs-comment"># 输入始发站:南京并输入回车以确认</span>
<span class="hljs-keyword">from</span>StationText.send_keys(<span class="hljs-string">"南京"</span>)
<span class="hljs-keyword">from</span>StationText.send_keys(Keys.ENTER)
除了回车外,Keys 类还提供了其它常用键盘键以供使用:
| 操作 | 属性 |
|---|---|
| 删除键 | send_keys(Keys.BACK_SPACE) |
| 空格键 | send_keys(Keys.SPACE) |
| 制表键 | send_keys(Keys.TAB) |
| 回退键 | send_keys(Keys.ESCAPE) |
| 回车 | send_keys(Keys.ENTER) |
| 全选 | send_keys(Keys.CONTRL,‘a’) |
| 复制 | send_keys(Keys.CONTRL,‘c’) |
| 剪切 | send_keys(Keys.CONTRL,‘x’) |
| 粘贴 | send_keys(Keys.CONTRL,‘x’) |
| 键盘F1 | send_keys(Keys.F1) |
模仿始发地输入,不难写出到达地和乘车日期的的输入代码,这里不再赘述。
3.5 模拟鼠标输入
模拟鼠标输入我们需要引入 ActionChains 类。
from selenium<span class="hljs-selector-class">.webdriver</span>
<span class="hljs-selector-class">.common</span>
<span class="hljs-selector-class">.action_chains</span> import ActionChains
在第二节的实践中,我们发现查询按钮只能通过鼠标点击确认;ActionChains 类提供了一系列鼠标输入方法让我们达成目标。
我们首先获取查询按钮的 html 代码:
<span class="hljs-params"><a href="javascript:void(<span class="hljs-number">0</span>)" class="btn btn-primary form-block" id="search_one"></span>查<span class="hljs-variable"> </span>;<span class="hljs-variable"> </span>;<span class="hljs-variable"> </span>;<span class="hljs-variable"> </span>;询<span class="hljs-params"></a></span>
通过以下代码实现单击查询按钮的效果:
<span class="hljs-meta"># 定位提交按钮元素</span>
searchOne = browser.find_element(By.ID, value=<span class="hljs-string">'search_one'</span>)
<span class="hljs-meta"># 创建 ActionChains 对象</span>
actions = ActionChains(browser)
<span class="hljs-meta"># 单击提交按钮</span>
actions.click(searchOne).perform()
需要注意一下,这里的
actions.click(element)只是定义了一个操作(单击某个元素),但此时操作还不会实际执行,只是被暂存在 ActionChains 的队列中。.perform()这个方法才是触发执行所有已排队操作的关键。没有它,操作只会被记录而不会实际发生。
除了单击外,ActionChains 类还提供了其它点击方式以供使用:
| 操作 | 函数 |
|---|---|
| 右击 | context_click() |
| 双击 | double_click() |
| 拖拽 | double_and_drop() |
| 悬停 | move_to_element() |
3.5 延时等待
经过上面的学习与分析,我们写出了这样的代码:
<span class="hljs-comment"># 出发站输入框元素输入与确认 </span>
fromStationText = browser.find_element(<span class="hljs-keyword">by</span>=By.ID,<span class="hljs-built_in">value</span>=<span class="hljs-string">'fromStationText'</span>)
fromStationText.<span class="hljs-built_in">clear</span>()
fromStationText.send_keys(<span class="hljs-string">"南京"</span>)
fromStationText.send_keys(Keys.ENTER)
<span class="hljs-comment"># 到达地输入框元素输入与确认 </span>
toStationText = browser.find_element(<span class="hljs-keyword">by</span>=By.ID,<span class="hljs-built_in">value</span>=<span class="hljs-string">'toStationText'</span>)
toStationText.<span class="hljs-built_in">clear</span>()
toStationText.send_keys(<span class="hljs-string">"上海"</span>)
toStationText.send_keys(Keys.ENTER)
<span class="hljs-comment"># 出发日期输入框元素输入与确认 </span>
trainDate = browser.find_element(<span class="hljs-keyword">by</span>=By.ID,<span class="hljs-built_in">value</span>=<span class="hljs-string">'train_date'</span>)
trainDate.<span class="hljs-built_in">clear</span>()
trainDate.send_keys(<span class="hljs-string">"2025-06-02"</span>)
trainDate.send_keys(Keys.ENTER)
<span class="hljs-comment"># 单击查询按钮 </span>
searchOne = browser.find_element(By.ID, <span class="hljs-built_in">value</span>=<span class="hljs-string">'search_one'</span>)
actions = ActionChains(browser)
actions.click(searchOne).perform()
运行测试结果如下:
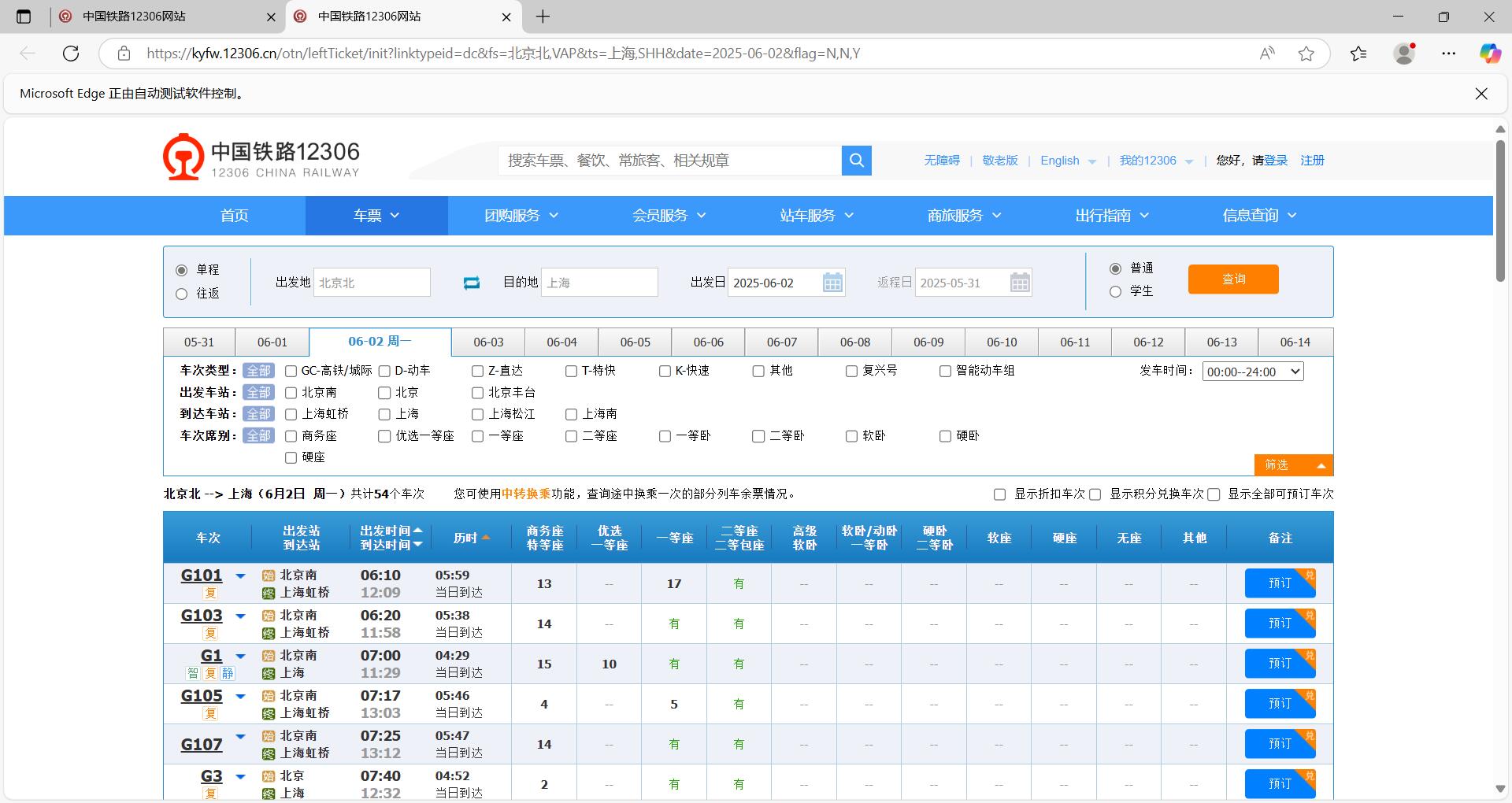
你会发现,为什么我们查询到的是北京到上海的车?打开上一个界面,我们可以看到:
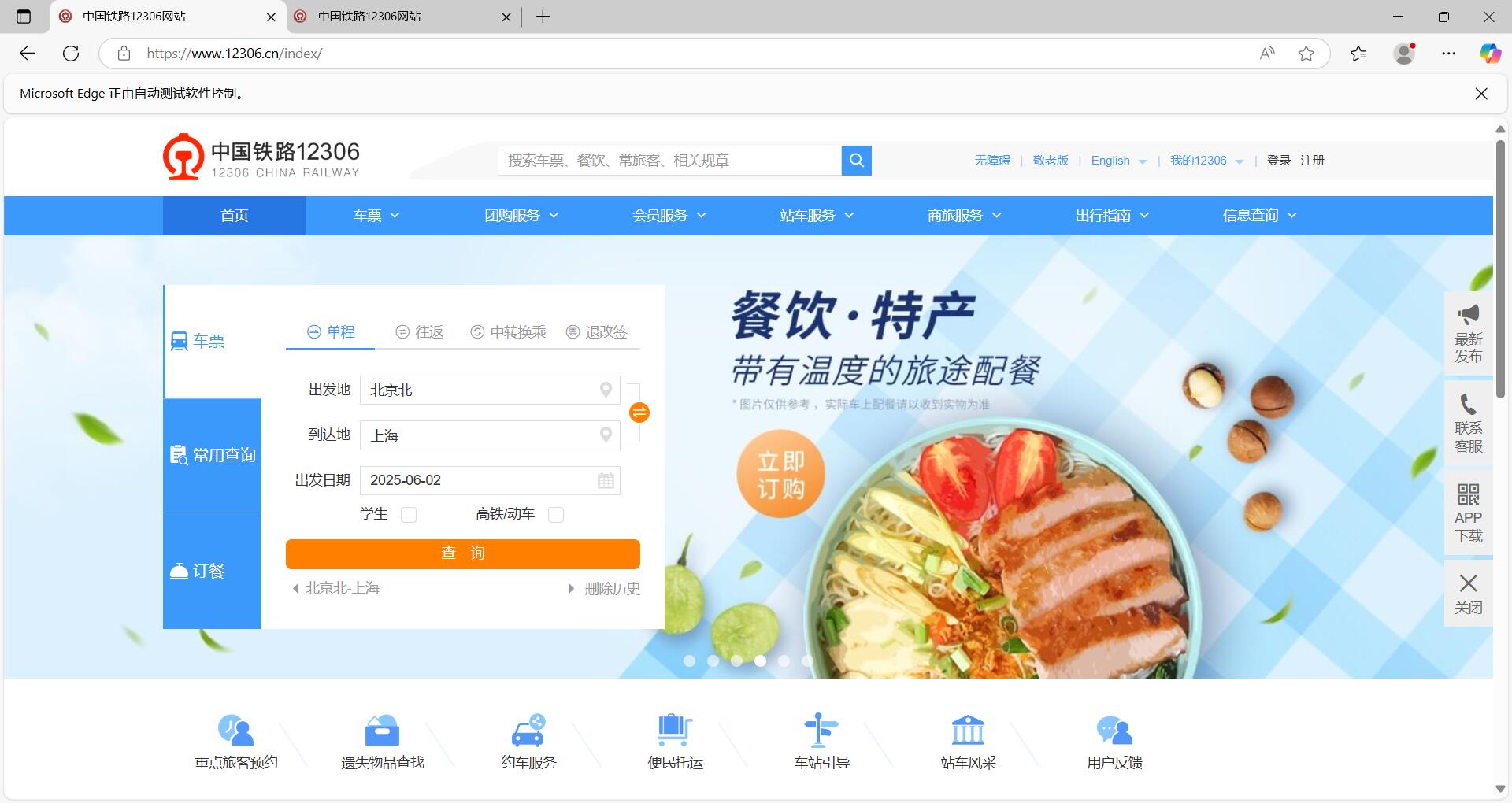
我们的出发地为北京北,并不是我们所输入的南京!所以在 Selenium 中,等待机制是确保页面元素加载完成后再进行操作的关键。由于 12306 网页加载速度受网络、服务器性能等因素影响,直接操作未加载完成的元素会导致脚本失败,也就是南京没有能被正确输入到出发地输入框中,取代的是默认值北京北。
注意,这个错误可能是不可复制的。在大部分电脑上,不设置等待也能正常输入南京南。本文的错误是在特定网络情况下人为造成,仅供演示为什么我们需要等待机制。
我们可以通过多种方式进行等待,分别是固定等待、隐式等待、显式等待和 Fluent Wait 等。本文仅介绍固定等待和隐式等待,更多的等待机制可以在等待机制中进行学习。
固定等待很简单,用过 time.sleep(n) 强制等待 n 秒即可。
注意,需要在
browser.get(url),之后执行。这是因为 Selenium 只会等待浏览器返回 HTTP 响应(即页面开始加载),但不会等待AJAX 动态内容、图片、CSS、JS 等资源等完全加载,所以我们要在get()后等待它们加载完成。
隐式等待是一种全局性的等待机制,它会在查找元素时等待一定的时间。如果在指定的时间内找到了元素,Selenium 会立即继续执行后续操作;如果超时仍未找到元素,则会抛出 NoSuchElementException 异常。隐式等待通过 implicitly_wait() 方法来设置。这个方法只需要调用一次,之后的所有元素查找操作都会遵循这个等待时间。
隐式等待的基本方法如下:
<span class="hljs-meta"># 初始化浏览器对象</span>
browser = webdriver.Edge()
<span class="hljs-meta"># 设置隐式等待时间为 5 秒 </span>
browser.implicitly_wait(<span class="hljs-number">5</span>)
browser.<span class="hljs-keyword">get</span>(<span class="hljs-string">"https://www.12306.cn/index/"</span>)
<span class="hljs-meta"># 出发站输入框元素输入与确认 </span>
fromStationText = browser.find_element(by=By.ID,value=<span class="hljs-string">'fromStationText'</span>)
现在我们进行测试,发现成功查询到我们所需要的:
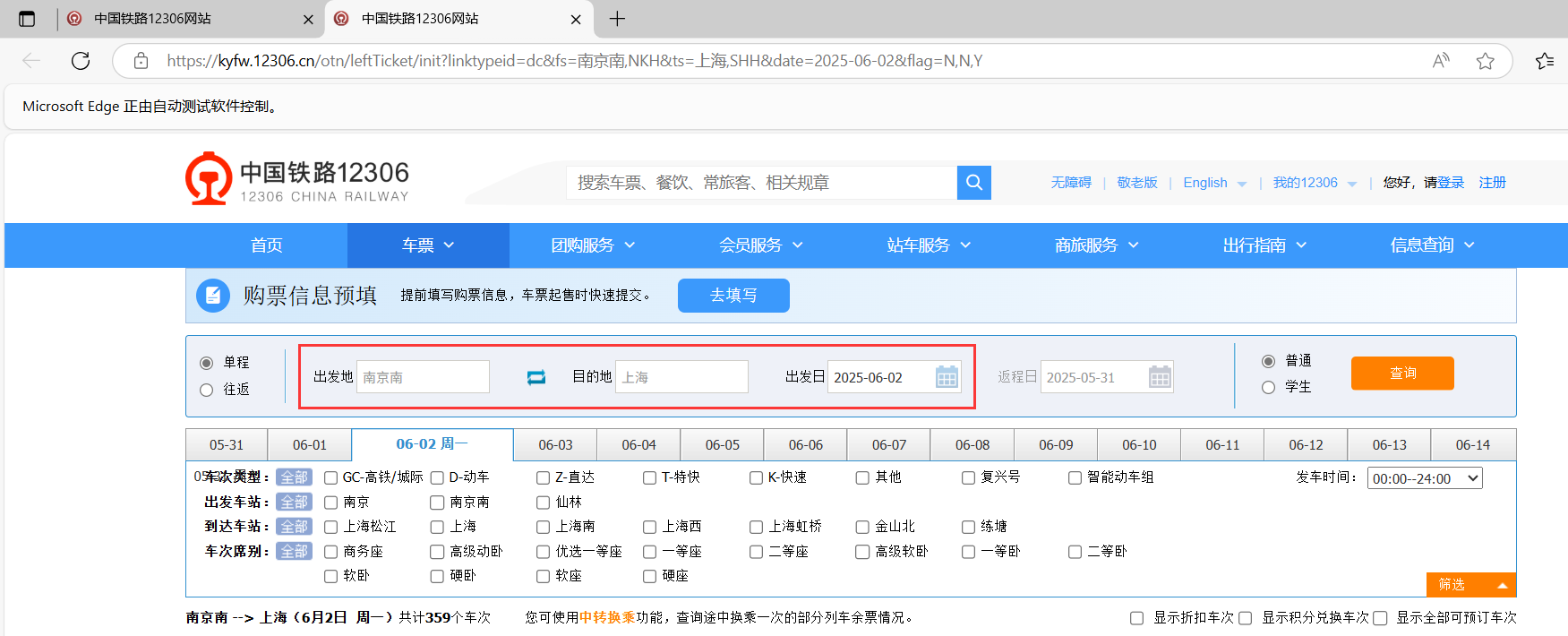
至此,第一步成功完成!
4. Selenium 进阶用法
在完成第一步时,我们介绍了简单的 Selenium 用法,但在后面的任务中,简单的用法无法满足我们的需求,所以必须学习 Selenium 的进阶用法以完成给定场景所有的测试任务。
在第二步中,我们需要在查询结果页面对车次类型、出发车站、到达车站、发车时间进行筛选,选择智能动车组、南京南站、上海虹桥站、发车时间范围 12 点至 18 点。
4.1 使用 XPath 进行元素定位
选定智能动车组的 checkbox 元素,我们发现它的 ID 是一个很奇怪的字符串。
<input name=<span class="hljs-string">"cc_type"</span> value=<span class="hljs-string">"智"</span> <span class="hljs-class"><span class="hljs-keyword">type</span></span>=<span class="hljs-string">"checkbox"</span> <span class="hljs-class"><span class="hljs-keyword">class</span></span>=<span class="hljs-string">"check"</span> id=<span class="hljs-string">"checkbox_3FghhQ3Twp"</span> aria-label=<span class="hljs-string">"车次类型为:智能动车组,按空格键进行操作"</span>>
其实,这类 ID 可能是动态生成的,每次查询时不同,不能硬编码在代码里。所以我们只能通过 其他固定属性 或 关联文本 来定位元素。XPath 给我们提供了这样的方法。
XPath (XML Path Language) 是一种用于在 XML 和 HTML 文档中定位节点的查询语言。在 Selenium WebDriver 中,XPath 是一种非常强大的元素定位方式,特别适用于处理动态元素、复杂DOM结构和没有固定ID/Class的元素,以下是常见的 XPath 定位方式:
<span class="hljs-comment"># 绝对路径(从根开始)</span>
driver.find_element(By.<span class="hljs-keyword">XPATH</span>, <span class="hljs-string">"/html/body/div/form/input"</span>)
<span class="hljs-comment"># 相对路径(任意位置)</span>
driver.find_element(By.<span class="hljs-keyword">XPATH</span>, <span class="hljs-string">"//input"</span>)
<span class="hljs-comment"># 通过属性定位</span>
driver.find_element(By.<span class="hljs-keyword">XPATH</span>, <span class="hljs-string">"//input[@id='username']"</span>)
driver.find_element(By.<span class="hljs-keyword">XPATH</span>, <span class="hljs-string">"//input[@type='text']"</span>)
<span class="hljs-comment"># 通过文本内容定位</span>
driver.find_element(By.<span class="hljs-keyword">XPATH</span>, <span class="hljs-string">"//button[text()='登录']"</span>)
<span class="hljs-comment"># 通过部分属性值定位</span>
driver.find_element(By.<span class="hljs-keyword">XPATH</span>, <span class="hljs-string">"//input[contains(@id,'user')]"</span>)
driver.find_element(By.<span class="hljs-keyword">XPATH</span>, <span class="hljs-string">"//input[starts-with(@name,'email')]"</span>)
当然,你也可以在元素定位方法学习其它更详细的 XPath 定位方式。
多次刷新,我们发现 aria-label 属性是固定不变的(当然你也可以使用其它不变的属性),所以我们可以通过 aria-label 属性进行定位:
<span class="hljs-attr">trainType</span> = browser.find_element(By.XPATH, <span class="hljs-string">"//input[@aria-label='车次类型为:智能动车组,按空格键进行操作']"</span>)
对于南京南站,上海虹桥站,以及出发时间的选择,由于 ID 不变,所以我们常规通过 ID 定位即可,可以写出下面的代码:
<span class="hljs-comment"># 选择智能动车组 </span>
trainType = browser.find_element(By.XPATH, <span class="hljs-string">"//input[@aria-label='车次类型为:智能动车组,按空格键进行操作']"</span>)
trainType.click()
<span class="hljs-comment"># 选择出发车站:南京南 </span>
fromStation = browser.find_element(By.ID, <span class="hljs-built_in">value</span>=<span class="hljs-string">'cc_from_station_南京南_check'</span>)
fromStation.send_keys(Keys.<span class="hljs-literal">SPACE</span>)
<span class="hljs-comment"># 选择到达车站:上海虹桥 </span>
toStation = browser.find_element(By.ID, <span class="hljs-built_in">value</span>=<span class="hljs-string">'cc_to_station_上海虹桥_check'</span>)
toStation.send_keys(Keys.<span class="hljs-literal">SPACE</span>)
<span class="hljs-comment"># 选择发车时间:12:00 ~ 18:00 </span>
startTime = browser.find_element(By.ID, <span class="hljs-built_in">value</span>=<span class="hljs-string">'cc_start_time'</span>)
startTime.send_keys(Keys.ARROW_DOWN)
startTime.send_keys(Keys.ARROW_DOWN)
startTime.send_keys(Keys.ARROW_DOWN)
startTime.send_keys(Keys.ENTER)
运行文件,你会发现一个报错:
E:\2024-code\Webtest-Selenium\InstallTest.py Traceback (most recent <span class="hljs-keyword">call</span> <span class="hljs-keyword">last</span>): <span class="hljs-keyword">File</span> <span class="hljs-string">"E:\2024-code\Webtest-Selenium\InstallTest.py"</span>, line <span class="hljs-number">41</span>, <span class="hljs-keyword">in</span> <<span class="hljs-keyword">module</span>> trainType = browser.find_element(By.XPATH, <span class="hljs-string">"//input[@aria-label='车次类型为:智能动车组,按空格键进行操作']"</span>) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ <span class="hljs-keyword">File</span> <span class="hljs-string">"E:\2024-code\Webtest-Selenium\.venv\Lib\site-packages\selenium\webdriver\remote\webdriver.py"</span>, line <span class="hljs-number">914</span>, <span class="hljs-keyword">in</span> find_element <span class="hljs-keyword">return</span> self.execute(Command.FIND_ELEMENT, {<span class="hljs-string">"using"</span>: <span class="hljs-keyword">by</span>, <span class="hljs-string">"value"</span>: <span class="hljs-keyword">value</span>})[<span class="hljs-string">"value"</span>]
出现这个报错的原因是因为脚本无法找到我们指定的页面元素。可是我们已经用 XPath 精准定位到了,为什么还会有这样的错误呢?
4.2 切换窗口焦点
在第三节的页面操作过程中,我们点击提交按钮后弹出了新窗口,焦点在旧窗口中是显然找不到元素的,所以我们需要切换焦点到新弹出的窗口中。
具体方法是:
- 首先获取当前窗口的句柄
browser.current_window_handle; - 接着打开弹出新窗口,获得当前打开的所有窗口的句柄
browser.window_handles并通过for循环遍历handle; - 如果不等于第一次打开窗口的句柄,那么一定是新窗口的句柄,因为执行过程只打开了两个窗口;
代码实现如下:
<span class="hljs-meta"># 获取 12306 网页 </span>
browser.<span class="hljs-keyword">get</span>(<span class="hljs-string">"https://www.12306.cn/index/"</span>)
<span class="hljs-meta"># 记录当前窗口句柄 </span>
original_window = browser.current_window_handle
<span class="hljs-meta"># ... 其余的代码</span>
<span class="hljs-meta"># 点击查询按钮,跳转至查询页</span>
actions.click(searchOne).perform()
<span class="hljs-meta"># 切换到新窗口 </span>
<span class="hljs-keyword">for</span> handle in browser.window_handles:
<span class="hljs-keyword">if</span> handle != original_window:
browser.switch_to.window(handle)
<span class="hljs-keyword">break</span>
现在测试,会发现选择全部成功:
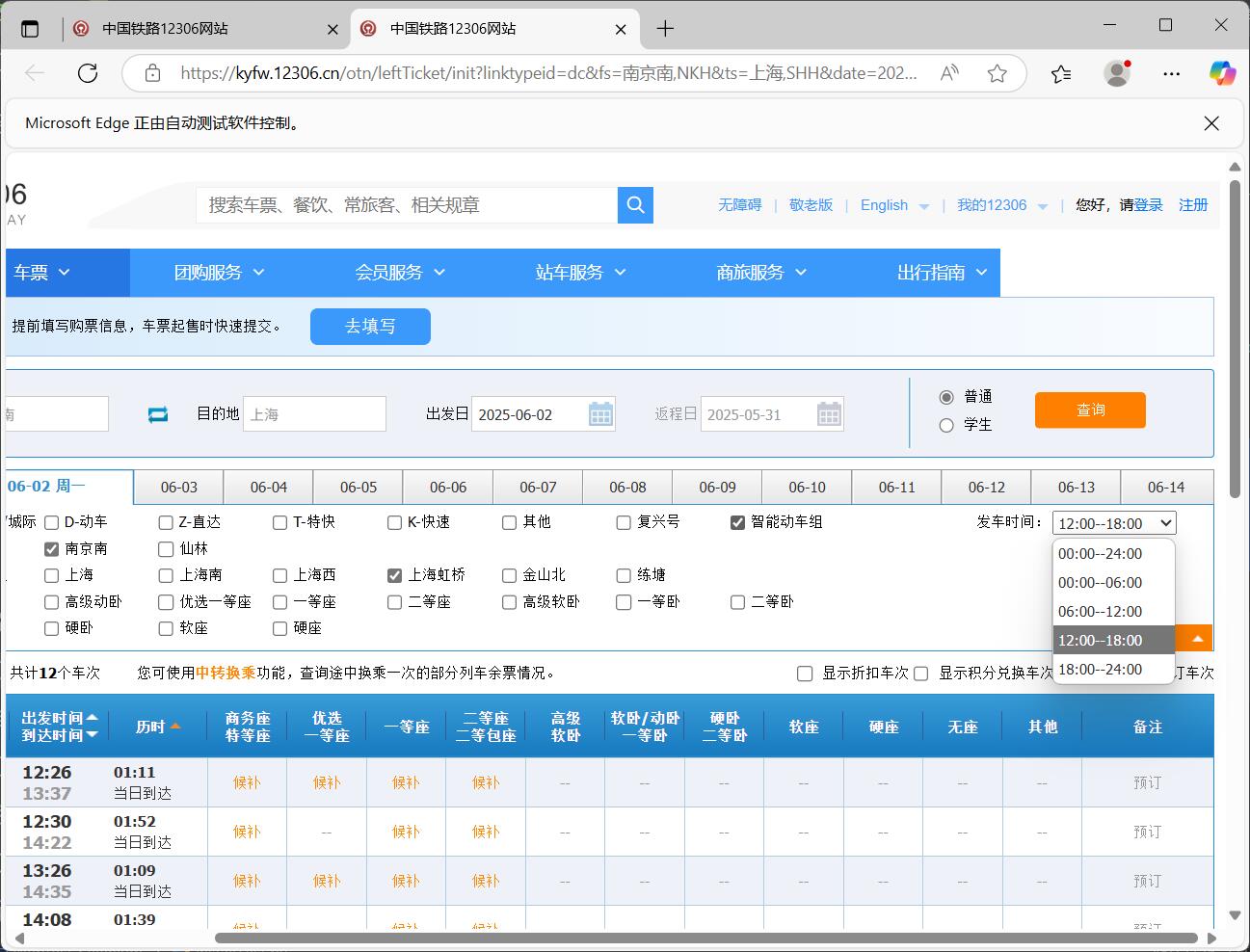
至此,第二步圆满完成!
4.3 Selenium中获取元素的值
第三步中要求我们获取符合要求的车次数量、历时最短的车次号和彻底的出发时间与到达时间并输出至控制台,所以我们需要学习从 Selenium 中获取元素的值。
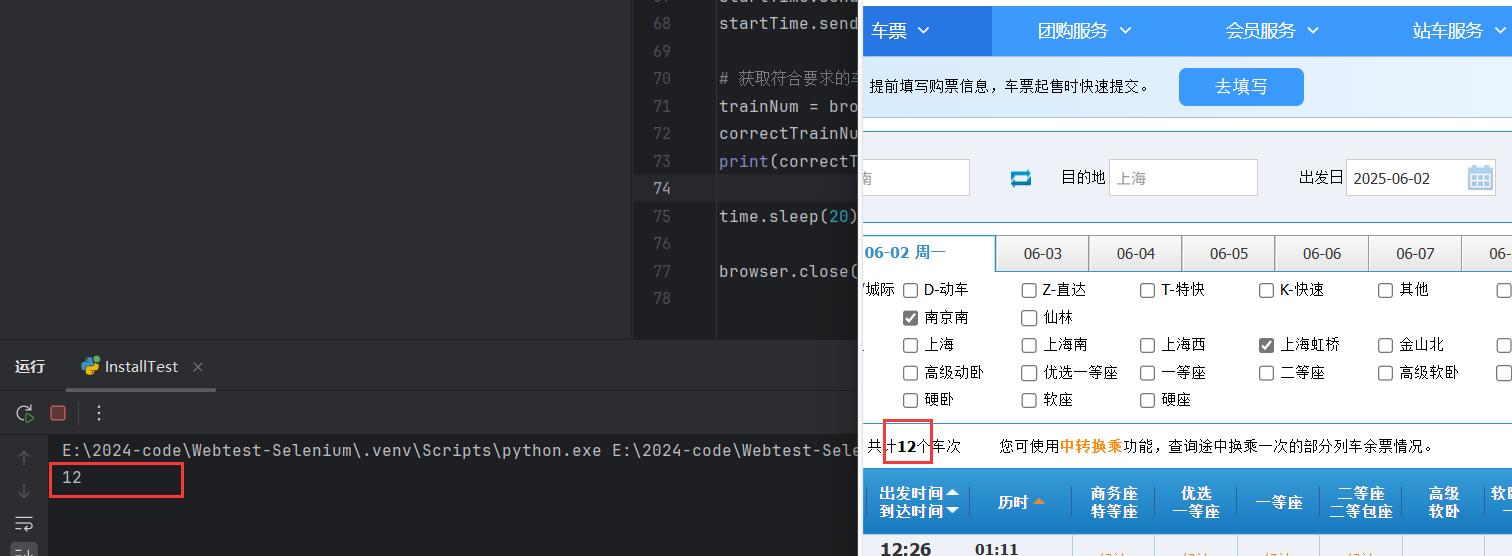
首先利用开发者工具选择车次数量,获得其 html 代码如下:
<span class="hljs-tag"><<span class="hljs-name">strong</span> <span class="hljs-attr">id</span>=<span class="hljs-string">"trainum"</span>></span>12<span class="hljs-tag"></<span class="hljs-name">strong</span>></span>
我们可以通过如下代码获取车次元素的文本并打印至控制台:
trainNum = browser.find_element(By<span class="hljs-selector-class">.ID</span>, value=<span class="hljs-string">'trainum'</span>)
correctTrainNum = trainNum<span class="hljs-selector-class">.text</span>
<span class="hljs-function"><span class="hljs-title">print</span>
<span class="hljs-params">(correctTrainNum)</span></span>
测试结果如下:
当然除了文本以外,我们也可以通过元素的 get_attribute("attribute_name") 方法来获取元素的指定属性值(如 value, href, class)等。
4.4 Selenium 获取多个元素
接下来我们要获得历时最短的车次号以及它的发车与到达时间。一个一个手动获取元素再进行比较当然是可以的,不过自动化测试嘛就是为了减轻人力负担,所以我们还是采用更加简便的方式来达到目的。
通过开发人员工具我们可以发现,符合条件的所有车次是被包含在一张 html 表里的,如下图所示:
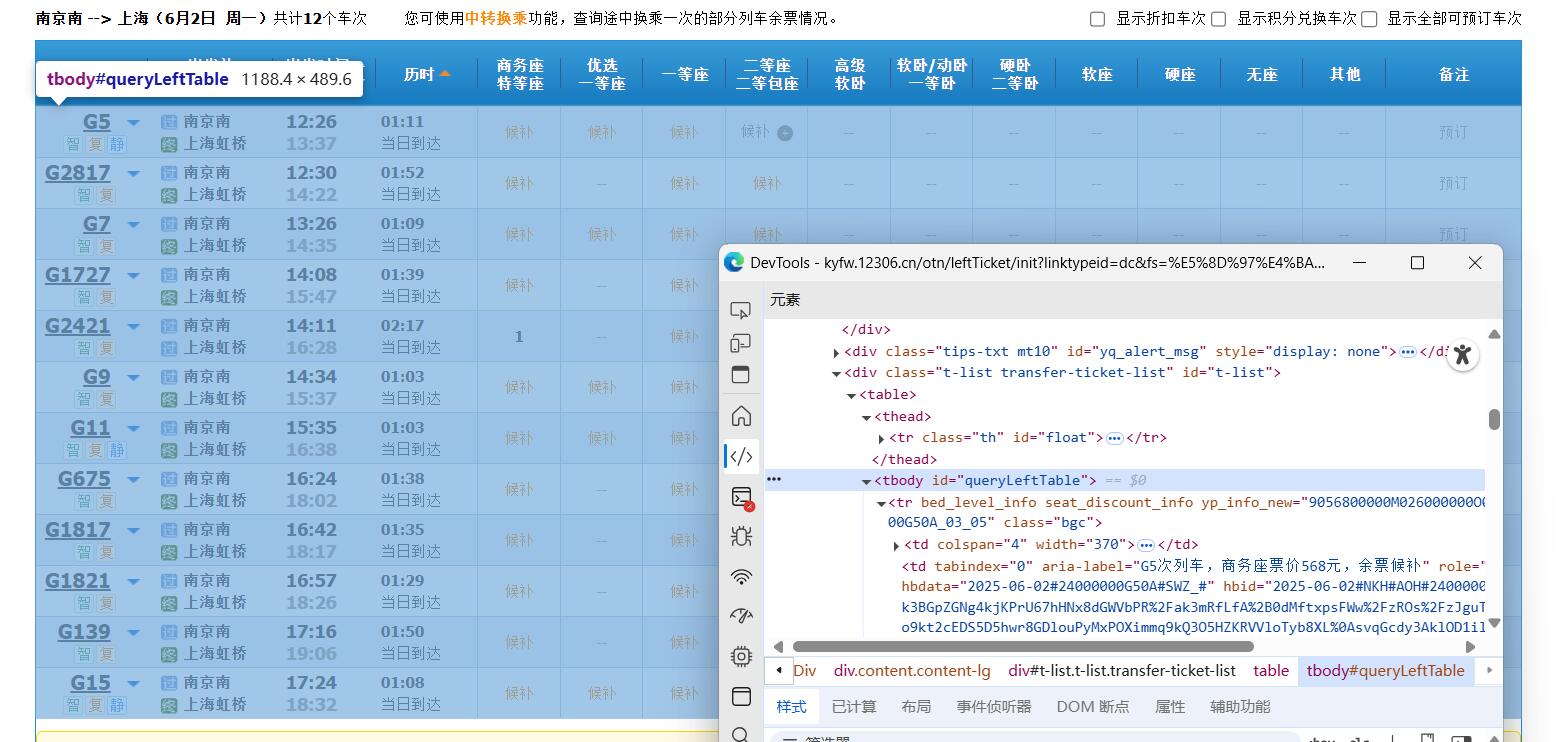
而我们再在这张表的结构中探索,会发现每一个有子元素的 tr 行代表一个车次的信息,如图所示:
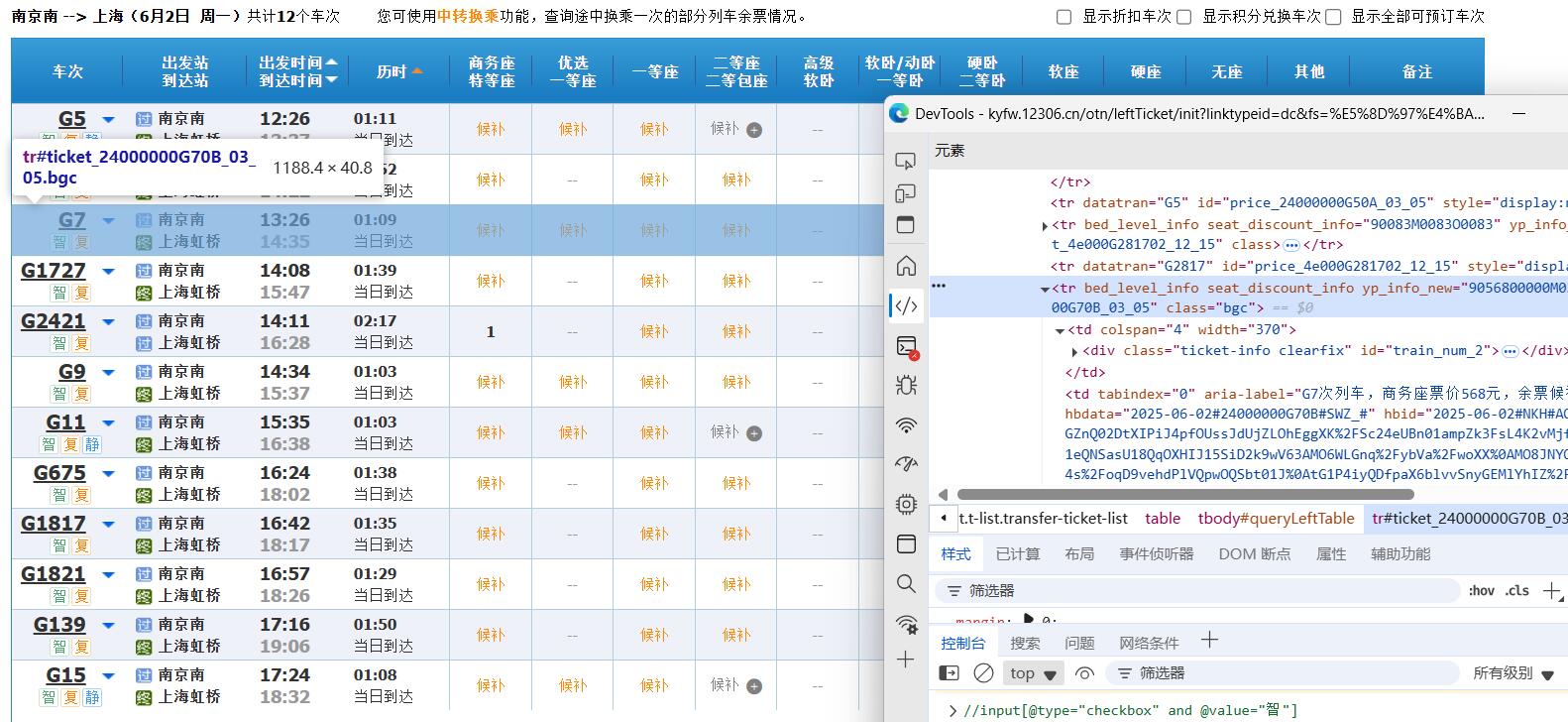
没有子元素的 tr 行是不显示的,也没有我们需要的车号与时间信息,如下图所示:

所以很明显,我们的目的是获取这张表中所有可显示的 tr 行。Selenium 提供了 find_elements 方法查找页面上所有匹配给定选择器的元素(返回列表),与之对应的是 find_element(只返回第一个匹配的元素)。我们可以通过如下代码来获得需要的车次行:
<span class="hljs-comment"># 获取符合条件的车次行 </span>
train_rows = <span class="hljs-keyword">browser.find_elements( </span>
<span class="hljs-keyword">By.XPATH, </span>
<span class="hljs-string">"//*[@id='queryLeftTable']//tr"</span>
)
取到我们需要的车号可以通过 CSS 选择器 ,注意略过不显示的行:
<span class="hljs-comment"># 遍历 train_rows,每隔一行取一个(步长为2) </span>
<span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> range(<span class="hljs-number">0</span>, len(train_rows), <span class="hljs-number">2</span>):
row = train_rows[i]
<span class="hljs-keyword">try</span>:
<span class="hljs-built_in">number</span> = row.find_element(By.CSS_SELECTOR, '<span class="hljs-keyword">div</span> > a').<span class="hljs-built_in">text</span>
print(<span class="hljs-built_in">number</span>)
except:
<span class="hljs-keyword">continue</span> <span class="hljs-comment"># 如果某一行找不到元素就跳过</span>
取到历时、出发时间和到达时间方法类似,这里不再赘述,给出代码实现如下:
<span class="hljs-comment"># 获取符合条件的车次行 </span>
train_rows = browser.find_elements(
By.XPATH,
<span class="hljs-string">"//*[@id='queryLeftTable']//tr"</span>
)
<span class="hljs-comment"># 遍历 train_rows,每隔一行取一个(步长为2) </span>
<span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> range(<span class="hljs-number">0</span>, len(train_rows), <span class="hljs-number">2</span>):
row = train_rows[i]
<span class="hljs-keyword">try</span>:
number = row.find_element(By.CSS_SELECTOR, value=<span class="hljs-string">'div > a'</span>).text <span class="hljs-comment"># 车号 </span>
start_time = row.find_element(By.CSS_SELECTOR, value=<span class="hljs-string">'.start-t'</span>).text <span class="hljs-comment"># 始发时间 </span>
end_time = row.find_element(By.CSS_SELECTOR, value=<span class="hljs-string">'.color999'</span>).text <span class="hljs-comment"># 到达时间 </span>
duration = row.find_element(By.CSS_SELECTOR, value=<span class="hljs-string">'.ls > strong'</span>).text <span class="hljs-comment"># 历时 </span>
duration_minutes = parse_duration(duration)
train_info = {
<span class="hljs-string">'number'</span>: number,
<span class="hljs-string">'start_time'</span>: start_time,
<span class="hljs-string">'end_time'</span>: end_time,
<span class="hljs-string">'duration'</span>: duration,
<span class="hljs-string">'duration_minutes'</span>: duration_minutes
}
train_data.append(train_info)
<span class="hljs-keyword">if</span> duration_minutes < shortest_duration_minutes:
shortest_duration_minutes = duration_minutes
shortest_train = train_info
<span class="hljs-keyword">except</span> Exception <span class="hljs-keyword">as</span> e:
<span class="hljs-keyword">continue</span>
<span class="hljs-keyword">if</span> shortest_train:
print(<span class="hljs-string">"用时最短的车次信息:"</span>)
print(f<span class="hljs-string">"车号:{shortest_train['number']}"</span>)
print(f<span class="hljs-string">"出发时间:{shortest_train['start_time']}"</span>)
print(f<span class="hljs-string">"到达时间:{shortest_train['end_time']}"</span>)
print(f<span class="hljs-string">"历时:{shortest_train['duration']}"</span>)
<span class="hljs-keyword">else</span>:
print(<span class="hljs-string">"未找到有效车次信息。"</span>)
测试一下我们的代码是否正常工作:
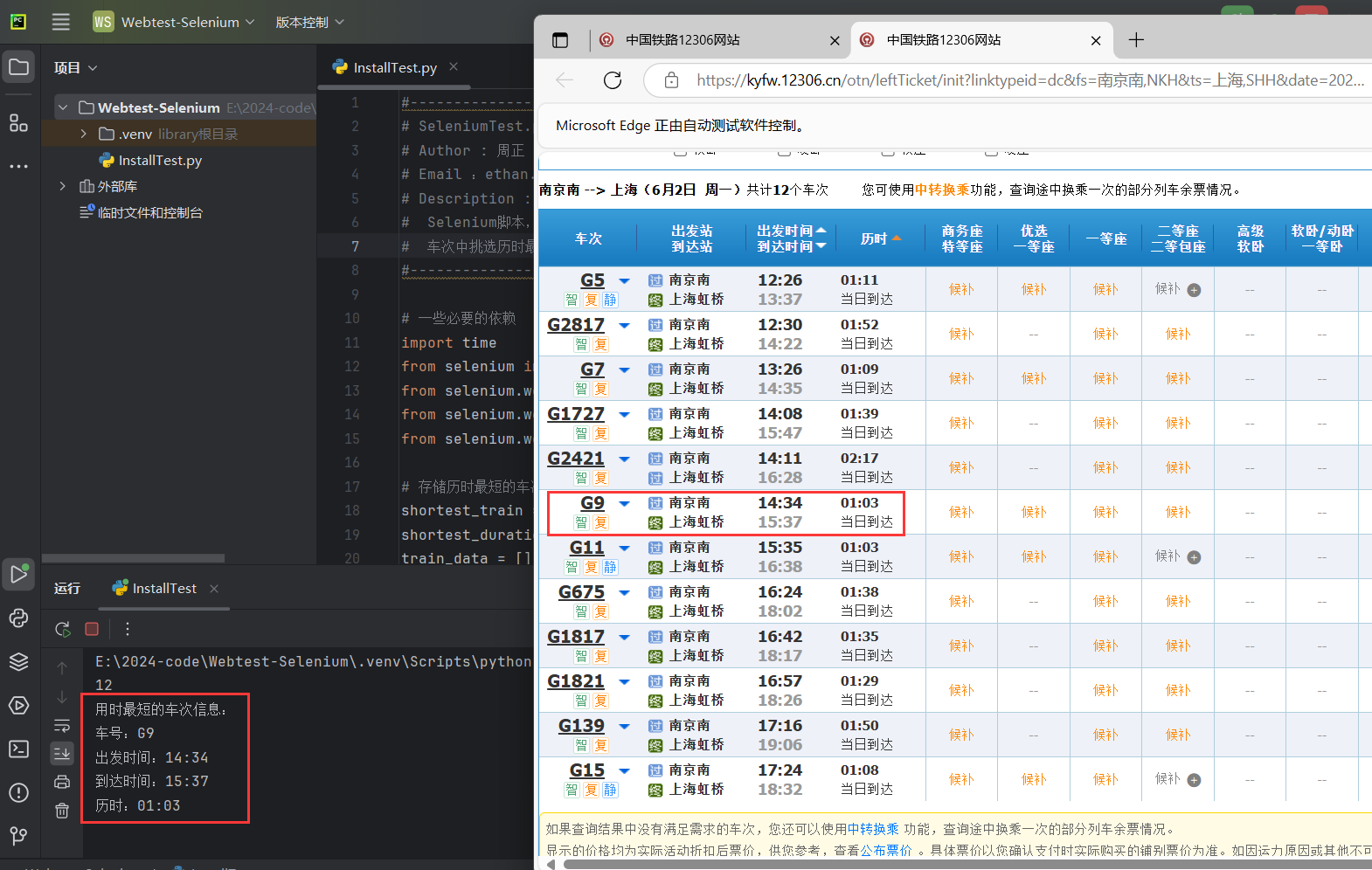
成功工作!至此步骤一、二和三圆满完成!
写给看完这篇文章的你
感谢你耐心阅读完这篇Selenium自动化测试实践指南!希望通过12306车票查询的案例,你能掌握从环境搭建到复杂场景测试的核心技能。自动化测试的魅力在于将重复劳动转化为精准高效的代码,而持续学习才是应对技术迭代的最佳策略。如果在实践中遇到任何问题,欢迎随时在评论区交流探讨。
参考文章
Selenium入门指南 Selenium 教程 | 菜鸟教程 Selenium + Python 中文文档 Selenium入门超详细教程——网页自动化操作 CSS 选择器 – CSS:层叠样式表 | MDN 八年测试经验,吐血整理出Selenium无法定位元素的几种解决方案